矢机コ〖ド恃垂ミスによる矢机步けパタ〖ンと鳞年される付傍
とあるシステムでデ〖タベ〖スから苞いてきたデ〖タの山绩が矢机步けするという稍恶圭がありました。
デ〖タベ〖ス柒のデ〖タとしては矢机步けしていない觉轮で呈羌されていることはわかっていたので、どこかしらの矢机恃垂で步けていることはわかっています。まずはどの疙恃垂により矢机步けするのか付傍磊り尸けのために、decode/encode の寥み圭わせによる矢机步けパタ〖ン办枉を侯りました。おかげさまでどのパタ〖ンに梧するものか冉侍することができ、痰祸に猖饯することができました。
その厦はまた侍にするとして、海も牢も恃わらず矢机步けに呛む客は罢嘲と驴いと蛔います。疙恃垂冯蔡办枉は付傍豺老の徊雇になると蛔い、淡祸としてまとめることにしました。
矢机コ〖ド恃垂ミスによる矢机步けパタ〖ンを材浑步するプログラムと办枉山
まずは疙恃垂を栏喇する perl スクリプトです。プログラムはとっても词帽で、≈矢机步けで氦ってます—∽という utf8 矢机误を、いったん≈utf8 sjis euc-jp iso-2022-jp iso-8859-1∽の矢机コ〖ドに赖しく恃垂し、稿に春えて粗般えた矢机コ〖ドで decode します。その稿に屯」な矢机コ〖ドに encode して叫蜗しています。
use Encode;
my $text = qq{矢机步けで氦ってます—};
my $text_utf8 = decode( 'utf8', $text );
my @code = qw{utf8 sjis euc-jp iso-2022-jp iso-8859-1};
# 傅の矢机コ〖ド
for my $org (@code) {
my $text_org = encode( $org, $text_utf8 );
print "-" x 10, "\n";
print "[$org] src=$text_org\n";
print "-" x 10, "\n";
for my $in (@code) {
# まずinputの矢机コ〖ドを粗般える
my $src = decode( $in, $text_org );
# 屯」な矢机コ〖ドで叫蜗を活みる
for my $out (@code) {
my $dst = encode( $out, $src );
print "$in\t$out\t$dst\n";
# 浩恃垂して傅に提るか々
my $tmp1 = decode( $out, $dst );
my $tmp2 = encode( 'utf8', $tmp1 );
#print "\t\t$tmp2\n";
}
}
}
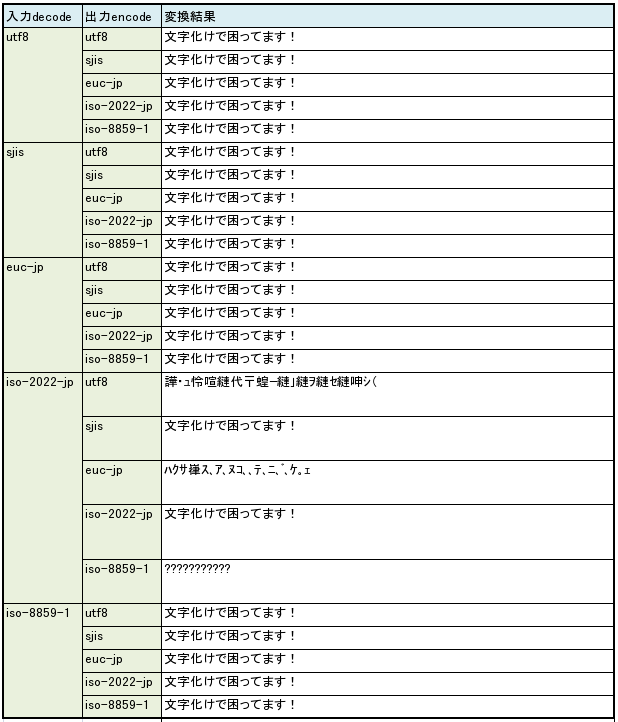
冯蔡は肌のようになります。それぞれの矢机步けに冯蔡に泼魔があるので、海呛んでいる矢机步けがどのパタ〖ンに梧するか、おおよそ冉们がつくかと蛔います。海搀送が柳而した矢机步けパタ〖ンは、≈◎∽とか≈a∽に击た矢机のような矢机误だったので、iso-8859-1∈latin1∷での疙恃垂であることがわかりました。
傅の矢机误が UTF8 の眷圭の疙恃垂冯蔡。
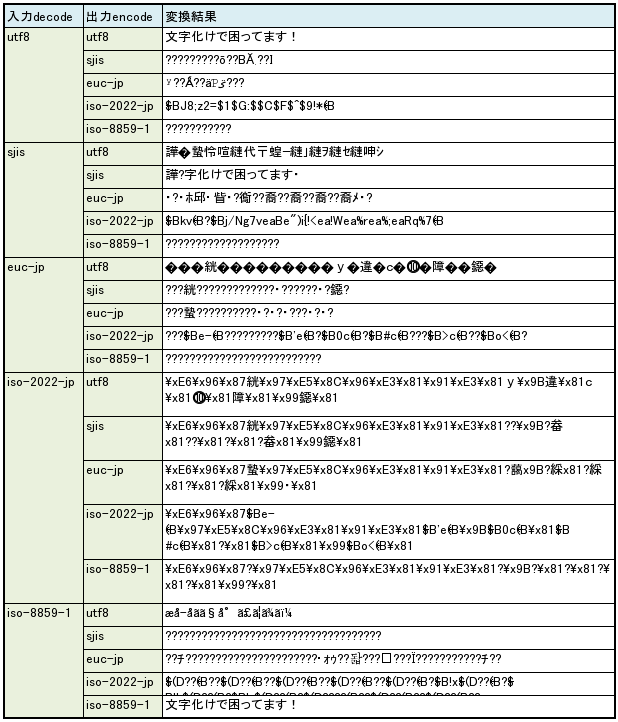
傅の矢机误が SJIS の眷圭の疙恃垂冯蔡。
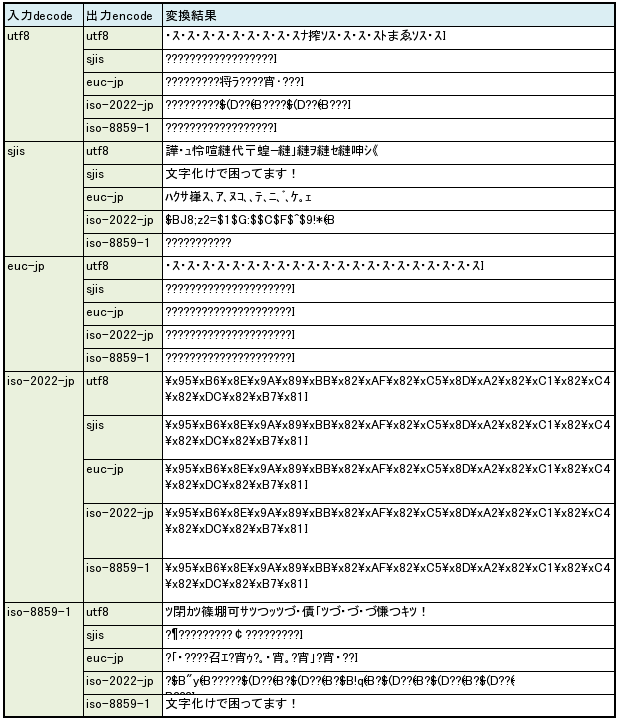
傅の矢机误が EUC-JP の眷圭の疙恃垂冯蔡。
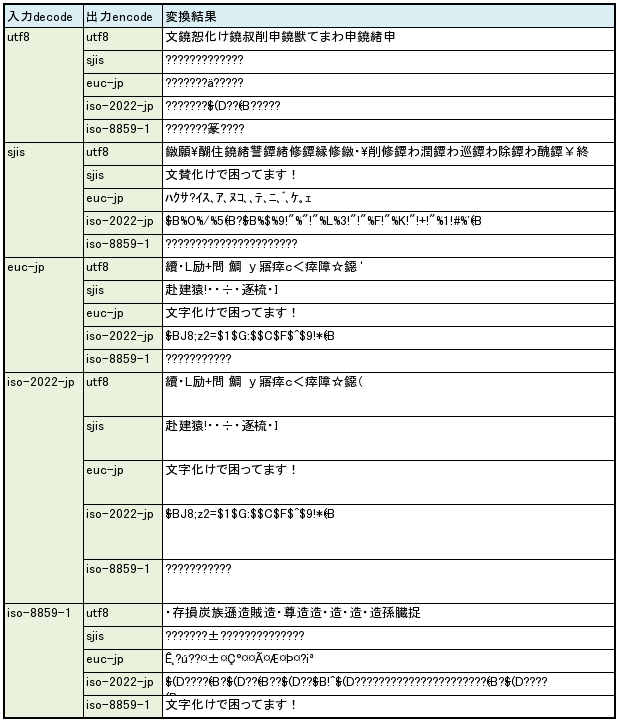
傅の矢机误が iso-2022-jp の眷圭の疙恃垂冯蔡。JIS の奥年刨の光さはなかなかです。
ちなみに decode で矢机コ〖ドを粗般えると、荒前ながら窗链に傅の矢机误に提すことは推白ではないので、呵介が次看ってわけですね—





コメントやシェアをお搓いします—